Machine learning modellen hebben data nodig om beter te worden. Maar veel van die nuttige data zit verstopt in losse notities en gespreksverslagen in medische dossiers. Google introduceerde afgelopen week zijn Healthcare Natural Language API. Daarmee kunnen onderzoekers en programmeurs gebruik maken van kant-en-klare AI-modellen om data uit dossiers te peuteren.
Wanneer dokters hun papieren dossiers vervangen door computers, zou je verwachten dat alle patiëntgegevens snel een eenvoudig te vinden zijn. En dat ze ook snel uit te wisselen zijn met andere zorgaanbieders. In de gezondheidszorg werken professionals al decennia met computers, en we weten inmiddels dus dat je ook in software naar een naald in een hooiberg kunt zoeken, en dat systeem A meestal niet overweg kan met patiëntgegevens uit dossier B.
Ongestructureerde data
De kern van dit probleem is dat heel veel data in medische dossiers is opgeslagen als zogeheten ongestructureerde data. Gestructureerde data is iets wat je invult bij een bepaald veld op het scherm, zoals bloeddruk of opnamedatum. Die data kun je relatief makkelijk terugvinden en uitwisselen (zolang zorgaanbieders allebei hetzelfde bedoelen met bloeddruk of opnamedatum, wat gek genoeg lang niet altijd zo is.)
Het beste voorbeeld van ongestructureerde data is alles wat dokters en verpleegkundigen invullen in de vrije velden van hun systeem, of de gespreksverslagen die als PDF worden geüpload. Deze vrije tekst bevat heel veel klinisch relevante informatie over medicatie, ziektegeschiedenis, behandelingen en de algehele toestand van een patiënt. Maar om iets met die data te kunnen doen moet je in de meeste gevallen al die notities handmatig doornemen en beoordelen. Zowel voor wetenschappelijk onderzoek, behandelingen en overplaatsingen van patiënten zou het praktisch zijn wanneer je het doorlezen en beoordelen van teksten in dossiers door software kon laten uitvoeren. Dat is geen nieuw idee: natural language processing bestaat al sinds de jaren zestig van de vorige eeuw.
Maar de recente stroomversnelling van technieken als deep learning en neurale netwerken heeft ervoor gezorgd dat het doorzoeken en bewerken van ongestructureerde data ordegroottes slimmer kan worden gedaan. De technologie die maakt dat Siri je begrijpt, dat auto’s deels vanzelf kunnen rijden, en Google Koreaans zo voor je vertaalt naar Swahili (Kweli!) is ook geschikt om een medisch dossier door te lezen en te voorspellen of iemand diabetes heeft, ook al is die informatie niet beschikbaar in een ja/nee veld.
Machine learning: Siri, zelfrijdende auto's en vertalen
De producten die Google afgelopen week aankondigde zijn geen kant-en-klare diensten waar je als dokter direct mee aan de slag kunt (tenzij je van een beetje programmeren houdt). Maar ze zorgen er wel voor dat onderzoekers, softwaremakers en ICT-afdelingen in ziekenhuizen op een gemakkelijker manier toegang krijgen tot krachtige AI technologie om natuurlijke taal in medische dossiers te analyseren en te classificeren. Ze krijgen daarmee een gereedschapskist in handen waardoor ze zelf veel minder hoeven te programmeren om dossiers te analyseren, en zich veel meer kunnen richten op hun specifieke vakgebied, of dat nu intensive care bewaking, geestelijke gezondheidszorg of medicatiebewaking is.
Hoe werkt het?
De Google Healthcare Natural Language API zoekt in documenten naar medische begrippen en inzichten zoals medische procedures, medicijnen, of medische aandoeningen. Daarbij moet Google rekening houden dat het feit dat dokters verschillende termen gebruiken om dezelfde aandoening te beschrijven. De deep learning modellen moeten ook snappen dat bepaalde medicatie in het verleden is voorgeschreven, of dat het stoppen ervan samenhangt met een bepaalde bijwerking die elders in het dossier staat. Domweg zoeken naar een specifiek woord werkt niet in zo’n dossier: je moet de context mee beoordelen. Bijvoorbeeld: heeft de patiënt zelf last van een bepaalde aandoening of gaat de notitie over een familielid met die aandoening?
De modellen van Google proberen alle beschikbare tekst te vertalen in een zo compleet mogelijk klinisch beeld van een patiënt, waarbij zoveel mogelijk (deels informeel gebruikte) medische termen worden omgezet in internationaal gestandaardiseerde terminologie stelsels zoals ICD-10. Dat is een systematische ordening van ziekten en aandoeningen die in klassen zijn ingedeeld en voorzien zijn van een code.
Net zoals een machine learning model een voorspelling kan doen of een foto een hond bevat, zo kan zo’n model op basis van tekst-analyse van het dossier een voorspelling doen of een patiënt eerder een hartaanval heeft gehad of nu diabetes heeft. Je zou verwachten dat het grootste deel van de medisch belangrijke informatie vastligt in gestructureerde data, in kolommen of tabellen. Dat is in de praktijk niet zo. Een behandelend arts gebruikt een dossier vooral vanuit het eigen behandelperspectief. Of bepaalde patiëntdata ook gebruikt kan worden voor wetenschappelijke onderzoeken of algoritmes om bijvoorbeeld complicaties te kunnen voorspellen is voor de dag-tot-dag behandeling niet relevant, dus die gegevens worden ook niet gestructureerd bijgehouden. Daarom treden bij deelname aan wetenschappelijke studies ook speciale protocollen in werking waarin je bepaalde gegevens weer wel bijhoudt.
Meeste data in tekstnotities
Een recente studie toonde aan dat het gestructureerde deel van patiëntendossiers maar een beperkt deel van de klinische geschiedenis vertelt, en dat de veel rijkere tekstnotitie een completer beeld opleveren. De dataset van het onderzoek bestond uit ruim tienduizend klinische notities met zowel gestructureerde als tekstdata. Aandoeningen als diabetes, hartproblemen of dementie bleken maar heel beperkt af te leiden te zijn uit de gestructureerde velden, maar wel af te leiden te zijn door het analyseren van de tekstvelden. De gestructureerde velden waren wat betrouwbaarder wanneer ze een bepaalde aandoening vastlegden, maar de deep learning modellen haalden met een acceptabele nauwkeurigheid veel meer gegevens boven water.
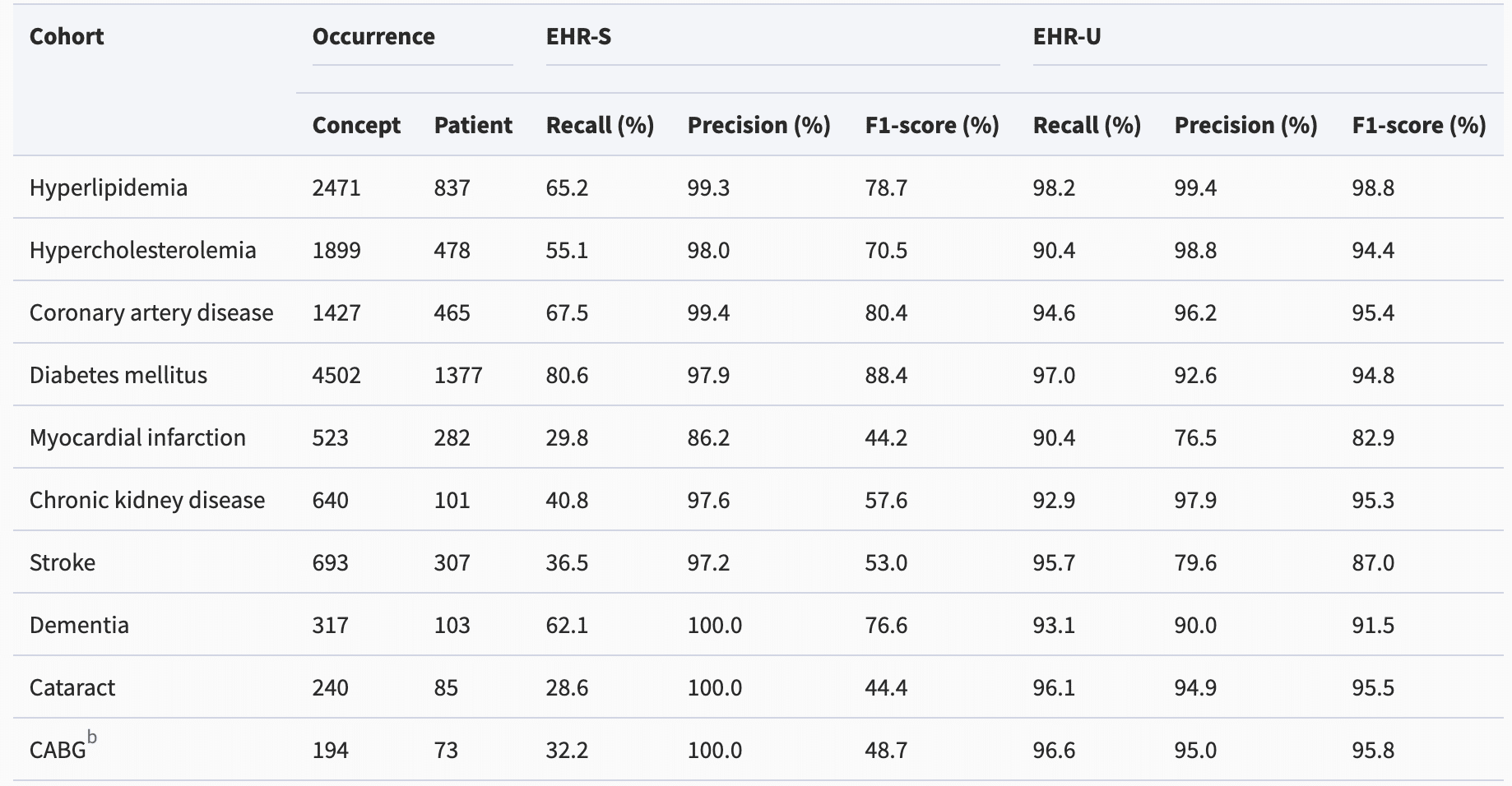
Aandoening vaak niet vastgelegd in gestructureerde informatie (EHR-S)
Je kunt je afvragen waarom het zo belangrijk is om bepaalde gegevens van een patiënt uit een dossier te kunnen traceren. Een van de belangrijkste redenen is dat dergelijke gegevens op hun beurt weer van groot belang kunnen zijn voor andere deep learning modellen, waarmee bijvoorbeeld bijwerkingen van medicaties, uitkomsten van behandelingen of complicaties kunnen worden voorspeld. Een andere nuttige toepassing is het veel sneller kunnen beoordelen of patiënten voldoen aan criteria voor gespecialiseerde onderzoeken op basis van hun dossier, in plaats van handmatige vragenlijsten of een EPD doorpluizen.
Tweehonderdduizend patiëntendossiers
De nieuwe AI-tools van Google komen niet echt als een verrassing. Google publiceerde in begin 2018 al een artikel waarin 34 (!) co-auteurs uitleggen hoe ze geanonimiseerde data uit ruim tweehonderdduizend patiëntendossiers gebruikten om modellen te ontwikkelen die voorspellingen kunnen doen over de opnametijd, de kans dat iemand later opnieuw moet worden opgenomen of zelfs overlijdt. Dergelijke statistische modellen hebben normaal gesproken grote hoeveelheden geschoonde en gecategoriseerde datapunten nodig.
Het centrale inzicht van die Google-studie was dat je al die gegevens niet handmatig hoeft te destilleren en te structureren uit de medische dossiers van patiënten. In plaats daarvan maakte Google gebruik van kunstmatige intelligentie, met name machine learning, om zelfs in slecht leesbare handschriften de relevante variabelen op te sporen waarmee ze hun voorspellende modellen kunnen ontwikkelen. Google-onderzoekers spraken vaak over de ‘voor-bewerker’ of de ‘pre-processor’ modellen die je nodig hebt om goede data te hebben, waarmee je vervolgens met AI-toepassingen in een bepaald vakgebied aan de slag kunt, zoals genetica, geneesmiddelenonderzoek of infectieziekten-bestrijding. Met de aankondigingen van afgelopen week heeft Google een deel van de voorbewerker-modellen, die eerst voor eigen gebruik ontwikkeld, zijn nu openbaar toegankelijk gemaakt als cloud-service.

Het rijk verre van alleen
Google heeft het rijk niet alleen. Er zijn ook in Europa inmiddels al tientallen, of misschien zelfs wel honderden, AI-startups die zich bezighouden met één of andere vorm van deep learning modellen en tekstdata. Amazon introduceerde al eerder een vergelijkbare service: Amazon Comprehend Medical. Dat is ook een cloud-service waarmee je zonder kennis van machine-learning medische informatie uit dossiers kunt afleiden. Amazon richt zich met zijn service wat minder specifiek op ontwikkelaars van machine learning modellen, maar meer op efficiency-voordelen voor ziekenhuizen en verzekeraars, die immers minder afhankelijk worden van menselijk invoer- en codeerwerk.
Het belang van AI voor de analyse van patiëntendossiers werd deze week ook nog eens onderstreept door de overname van Apixio. Dat is een Amerikaans AI-bedrijf dat zich volledige richt op het analyseren en classificeren van grote hoeveelheden ongestructureerde patiënt data, zoals aantekeningen en losse meetgegevens. Centene, een van de allergrootste Amerikaanse zorgorganisaties met 23 miljoen aangesloten leden of klanten, vindt deze technologie zo belangrijk dat Apixio voor een fors bedrag werd ingelijfd.
Business case, certificering, pilots en implementatie van kunstmatige intelligentie: het zijn thema's die tijdens de masterclass Kunstmatige intelligentie in de zorg terugkomen. De masterclass (12 ABAN-punten) vindt plaats in het voorjaar van 2021. Meer informatie over het programma en gastsprekers is te vinden via de website.





De vraag is of dit geschikt is voor de Nederlandse taal. Kom je wel op het gebied van Pacmed.
Nog niet nee. Als SNOMED National Release Center al erg ver met het vertalen van SNOMED. Onder het mom van Verbinden en innoveren met SNOMED. Dit gaat natuurlijk over innovatie. We zijn met meerdere Amerikaanse bedrijven in gesprek. Zij kunnen de vertaling zo gebruiken.
Naast een Nederlandstalig woordenboek van unieke concepten en alle synoniemen, is ook een grote hoeveelheid Nederlandstalige trainingsdata nodig om bovenstaande methodes voor het Nederlands te ontwikkelen. In het gerefereerde artikel wordt genoemd dat records van 216,221 patiënten gedeïdentificeerd zijn om de methodes op te ontwikkelen. Dat is nogal een project.
Voor Engelse taal bestaat ook de publiek beschikbare MIMIC-III dataset waarmee het makkelijk is om NLP methodes op te ontwikkelen. Voor het Nederlands bestaat een dergelijke dataset niet naar mijn weten. Het EMC Clinical Corpus zou hier bruikbaar voor kunnen zijn maar lijkt momenteel niet beschikbaar.
@pimvolkert:disqus Hoe pakken de bedrijven waarmee jullie samenwerken dit aan?
98% betrouwbaarheid acceptabel? Als per dossier 50 items herkend worden, dan zit er gemiddeld in elk dossier 1 fout. Als er per dossier maar 1 item herkend wordt, lopen er alsnog in Nederland een paar honderd duizend mensen met een fout in hun dossier rond. Hoe ga je die fouten herkennen? Hoe ga je voorkomen dat daardoor medische missers ontstaan? Hoe ga je die fouten corrigeren? Hoe voorkom je dat de verzekeraar je als zorg fraudeur aanmerkt op basis van zo een fout? Hoe voorkom je dat een systematische fout in de AI leidt tot valse onderzoeksresultaten? Ik deel het optimisme niet...
Hi Winfried, over welke 98 procent heb je het hier precies?
Oh, ik heb de wat meer optimistische cijfers uit de tabel in het artikel gepakt... Die tabel is overigens niet goed te lezen zonder toelichting.