Wie controleert eigenlijk de artificial intelligence (AI) algoritmen die als pilot of proof-of-concept massaal hun intrede doen in de zorg? En wat betekent de opkomst van AI voor de ‘oude’ big data toepassingen en algoritmen?
Tijdens een themamiddag die volgende week (12 juni) wordt georganiseerd, staan dit soort vragen centraal. Op die dag worden voor de tweede maal de Nederlandse Data Science Prijzen uitgereikt door De Koninklijke Hollandsche Maatschappij der Wetenschappen (KHMW) en de Big Data Alliance (BDA). Het gaat om prijzen voor het beste proefschrift in data science, de meest veelbelovende startup en bedrijven of overheden die big data en slimme algoritmen op een innovatieve manier hebben toegepast. Vorig jaar won digital health onderneming Quantib de prijs voor start-ups, met de toepassing om met data dementie sneller te diagnosticeren.
Nieuwe ethische vragen
De uitreiking komt in een tijd waarin de technologiegebieden AI en big data minder onomstreden zijn dan bij de vorige editie. Trump en Cambridge Analytica, verkeersdoden door zelfsturende auto’s, algoritmen die zonder dat we ze helemaal begrijpen diabetes of hartritmestoornissen voorspellen; het zijn maar enkele voorbeelden van toepassingen die nieuwe ethische vragen oproepen.
Het is dan ook niet verwonderlijk dat de organisatoren ook de gevaren van data-wetenschap willen belichten. De Amerikaanse wiskundige Cathy O’Neil, auteur van de wereldwijde bestseller Weapons of Math Destruction, die tijdens het programma spreekt over de gevaren van algoritmiek en big data, weet daar wel raad mee. O’Neil studeerde in Berkeley, promoveerde aan Harvard University en was wiskundehoogleraar aan het Amerikaanse Barnard College. Ze werkte ook in de financiële wereld op Wall Street als kwantitatief analist/ bedenker en bouwer van wiskundige financiële modellen. Tot de crisis uitbrak, waarna ze zich aansloot bij de Occupy-beweging.
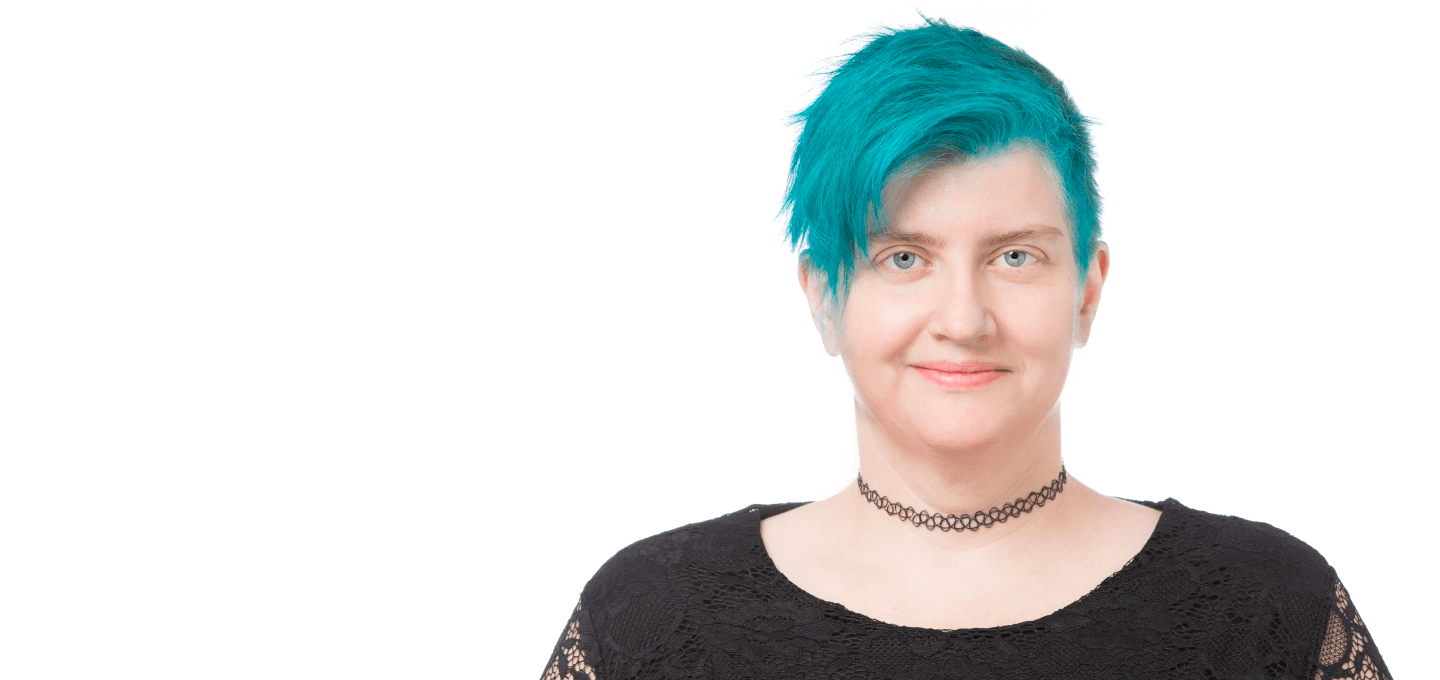
Mathbabe Cathy O'Neill
Op haar blog mathbabe.org waarschuwt ze al enkele jaren voor een te luchthartig gebruik van wiskundige modellen die op basis van big data in toenemende mate ons leven beheersen, zoals bij hypotheekaanvragen, sollicitaties en diagnostiek. “We zien modellen als goden, maar ze worden alleen begrepen door de hogepriesters van dit domein, wiskundigen en computerwetenschappers”, zegt ze in het voorwoord van haar boek.
Wij zijn Big Data
Ook de Nederlandse hoogleraar Sander Klous zal zich in een paneldiscussie met O’Neill buigen over vragen als of er een verbod moet komen op de algoritmiek die we niet honderd procent doorgronden. Of een verbod op bedrijven die niet transparant zijn over wat ze met onze data doen.
Klous is auteur van de bestseller Wij zijn Big Data. Hij is hoogleraar bij de Universiteit van Amsterdam (Big Data Ecosystems) en partner bij KPMG, verantwoordelijk voor data analytics. Toen Klous’ boek in 2014 uitkwam, was het begrip big data inmiddels bekend aan het raken bij het grote publiek, terwijl artificial intelligence nog aan zijn hype cycle moest beginnen. In eerste instantie was kunstmatige intelligentie ook erg afhankelijk van grote hoeveelheden data, bijvoorbeeld om systemen te trainen katten, honden, of fouten in laswerk te herkennen.
Inmiddels, zegt Klous, is er ook een generatie AI die geen grote hoeveelheden data nodig heeft om verbluffende resultaten te bereiken. Hij noemt het voorbeeld van AlphaGo, de software van AI bedrijf Deepmind die de menselijke wereldkampioen Lee Sedol in het oosters denkspel Go versloeg. De eerste versie van die software haalde zijn kennis uit een grote hoeveelheid analyses van ooit gespeelde partijen Go: big data dus. De laatste versie van de software, toepasselijk AlphaGo Zero genoemd, gebruikt nul kennis over door mensen gespeelde partijen Go, maar heeft door tegen zichzelf te spelen en daarvan te leren het niveau van een wereldkampioen bereikt. Klous legt uit dat je big data en AI als twee cirkels kunt zien die, afhankelijk van de toepassing, in min of meerdere mate overlappen.

Hij vergelijkt de huidige situatie van AI met die van big data in 2014. “Er waren pilots, proof-of-concepts en grotere IT-bedrijven al langer bezig met het gebruik van big data. Maar de meeste organisaties moesten nog worden overtuigd van de werkelijke waarde van de technologie. Dat kwartje is nu wel gevallen. Ik verwacht dat AI dezelfde ontwikkeling zal doormaken, en dat we dus nog enkele jaren nodig hebben voor de echte doorbraak.”
Big Data en AI projecten: agile en kleinschalig aanpakken
Klous wijst erop dat ondernemingen als Facebook, Google en Amazon wel veel ervaring hebben. “Die zijn allemaal al vanaf pakweg 2010 intensief bezig met het toepassen van zelflerende algoritmen, al dan niet in combinatie met big data. Daardoor hebben ze een enorme voorsprong.”
In de zorgsector klinken steeds vaker waarschuwende woorden wanneer het om de toepassing van big data en AI gaat. De toepassingen van zelflerende algoritmen op grote hoeveelheden bestaande data (ziekenhuisdossiers bijvoorbeeld) en nieuwe data (wearables, sensoren) levert bijna wekelijks wel nieuws op over voorspellende toepassingen. “Ik begrijp de motieven van de mensen die waarschuwen voor een te snelle toepassing van nieuwe algoritmen zonder gedegen bewijs of verder onderzoek”, zegt Klous. Hij geeft echter ook aan dat het niet om een alles of niets vraag gaat. “De toepassing van big data of AI in de zorgsector leent zich goed voor een zogeheten agile aanpak, waarbij je in een proof-of-concept setting onderzoekt of je aannames kloppen en verder bewijs verzamelt.”
Hij geeft een voorbeeld uit de psychiatrie, waarbij big data analyse aan het licht bracht waardoor sommige patiënten enkele dagen na hun opname agressief werden. Zij bleken kort voor hun opname nog drugs te hebben gebruikt, en leden aan ontwenningsverschijnselen. Het intake formulier vroeg wel naar druggebruik, maar niet of de patiënt 24 uur voor opname nog had gebruikt. “Die vraag werd toegevoegd, en na enkele maanden kon je vaststellen dat de medische staf beter kon anticiperen op deze groep. Het is een klein project, maar de effecten waren groot.”

Assurance nodig voor algoritmen
Een waarschuwing die ook vaak klinkt rond big data en AI is dat een gevonden correlatie nog niets zegt over oorzaak en gevolg. Klous onderschrijft dat, maar geeft tegelijk aan dat een gevonden correlatie nog steeds nut kan bewijzen, zelfs wanneer het oorzakelijke verband (nog) niet bekend is. Hij wijst op een voorbeeld dat Oxford professor Viktor Mayer-Schönberger in zijn boek De big data revolutie noemt.
Canadese big data onderzoekers kwamen erachter dat de vitale lichaamsfuncties van vroeggeboren babies zich in de 24 uur voordat een infectie optreedt stabiliseren. Dat lijkt voor de medische staf geruststellend, maar is dus een voorbode van een potentieel levensgevaarlijke situatie. Ook zonder het verband tussen de stabielere lichaamsfuncties en de infectie te kennen, kon hier eerder begonnen worden met een behandeling, omdat het algoritme een betrouwbare voorspeller was.
Klous is wel een groot voorstander van maximale transparantie over de onderliggende werking van algoritmen en eventueel de data die ze gebruiken. “Vanuit KPMG gaan wij ons steeds meer bezighouden met het verstrekken van assurance voor algoritmen, vergelijkbaar met de controle die we nu voor financiële jaarrekeningen uitvoeren. AI en big data mogen geen black box zijn, vooral niet wanneer ze steeds vaker worden toegepast voor kritische bedrijfsprocessen of zorgtoepassingen. Dat we de verbanden die algoritmen vinden niet meteen begrijpen is acceptabel, maar de algoritmen zelf moeten uitlegbaar en wetenschappelijk verantwoord zijn.”
Dinsdag 12 juni vindt de uitreiking van de Nederlandse Data science prijzen - georganiseerd door de De Koninklijke Hollandsche Maatschappij der Wetenschappen (KHMW) en de Big Data Alliance (BDA) - plaats. Aanmelden voor de themamiddag en en prijsuitreiking kan hier.



Trackbacks & Pingbacks
[…] met als intro: The $15 trillion question: Can you trust your AI? En de Amerikaanse wiskundige Cathy O’Neil schreef een wereldwijde bestseller (Weapons of Math Destruction) over de gevaren van algoritmiek […]
Plaats een Reactie
Meepraten?Draag gerust bij!